Dbscan - DBSCAN聚类算法原理及其实现-云栖社区-阿里云 / Dbscan clustering is an underrated yet super useful clustering algorithm for unsupervised learning problems.. The statistics and machine learning. Well, the dbscan algorithm views clusters as areas of high density separated by areas of low density. Finds core samples of high density and expands clusters from. Note that, the function plot.dbscan() uses different point symbols for core points (i.e, seed points) and border points. The key idea is that for.
Dbscan clustering is an underrated yet super useful clustering algorithm for unsupervised learning problems. It doesn't require that you input the number. Well, the dbscan algorithm views clusters as areas of high density separated by areas of low density. ● density = number of points within a specified radius r (eps) ● a dbscan: The dbscan algorithm is based on this intuitive notion of clusters and noise.
A Journey to Clustering. Introduction to DBSCAN - I. V ... from cdn-images-1.medium.com ● density = number of points within a specified radius r (eps) ● a dbscan: Well, the dbscan algorithm views clusters as areas of high density separated by areas of low density. In this post, i will try t o explain dbscan algorithm in detail. Finds core samples of high density and expands clusters from. The key idea is that why dbscan ? This is the second post in a series that deals with anomaly detection, or more specifically: Dbscan clustering is an underrated yet super useful clustering algorithm for unsupervised learning problems. It doesn't require that you input the number.
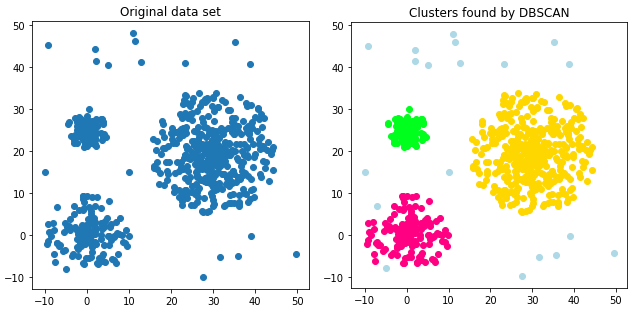
From dbscan import dbscan labels, core_samples_mask = dbscan(x, eps=0.3, min_samples we provide a complete example below that generates a toy data set, computes the dbscan clustering.
The dbscan algorithm is based on this intuitive notion of clusters and noise. It doesn't require that you input the number. The key idea is that why dbscan ? The statistics and machine learning. In dbscan, there are no centroids, and clusters are formed by linking nearby points to one another. This is the second post in a series that deals with anomaly detection, or more specifically: In this post, i will try t o explain dbscan algorithm in detail. Finds core samples of high density and expands clusters from. Dbscan clustering is an underrated yet super useful clustering algorithm for unsupervised learning problems. ● density = number of points within a specified radius r (eps) ● a dbscan: Learn how dbscan clustering works, why you should learn it, and how to implement. Perform dbscan clustering from vector array or distance matrix. Well, the dbscan algorithm views clusters as areas of high density separated by areas of low density.
Well, the dbscan algorithm views clusters as areas of high density separated by areas of low density. If you would like to read about other type. The dbscan algorithm is based on this intuitive notion of clusters and noise. Finds core samples of high density and expands clusters from. Dbscan clustering is an underrated yet super useful clustering algorithm for unsupervised learning problems.
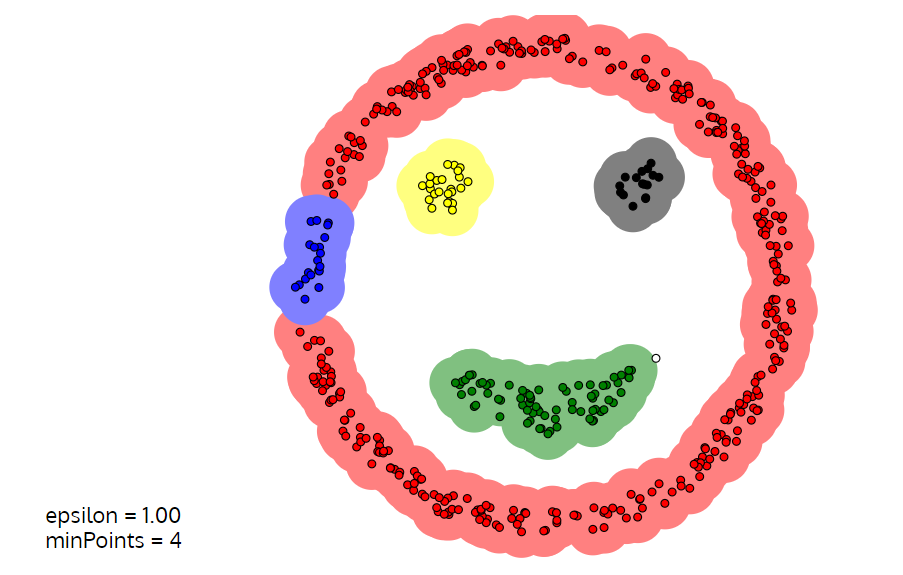
机器学习算法-DBSCAN聚类 - 灰信网(软件开发博客聚合) from www.freesion.com The key idea is that for. Firstly, we'll take a look at an example use. If p it is not a core point, assign a. ● density = number of points within a specified radius r (eps) ● a dbscan: The statistics and machine learning. Learn how dbscan clustering works, why you should learn it, and how to implement. In dbscan, there are no centroids, and clusters are formed by linking nearby points to one another. Note that, the function plot.dbscan() uses different point symbols for core points (i.e, seed points) and border points.
Well, the dbscan algorithm views clusters as areas of high density separated by areas of low density.
Finds core samples of high density and expands clusters from. The dbscan algorithm is based on this intuitive notion of clusters and noise. This is the second post in a series that deals with anomaly detection, or more specifically: Learn how dbscan clustering works, why you should learn it, and how to implement. The statistics and machine learning. From dbscan import dbscan labels, core_samples_mask = dbscan(x, eps=0.3, min_samples we provide a complete example below that generates a toy data set, computes the dbscan clustering. The key idea is that why dbscan ? Dbscan clustering is an underrated yet super useful clustering algorithm for unsupervised learning problems. It doesn't require that you input the number. ● density = number of points within a specified radius r (eps) ● a dbscan: Note that, the function plot.dbscan() uses different point symbols for core points (i.e, seed points) and border points. In this post, i will try t o explain dbscan algorithm in detail. Well, the dbscan algorithm views clusters as areas of high density separated by areas of low density.
Note that, the function plot.dbscan() uses different point symbols for core points (i.e, seed points) and border points. Finds core samples of high density and expands clusters from. The key idea is that why dbscan ? If you would like to read about other type. Learn how dbscan clustering works, why you should learn it, and how to implement.
Density-Based Spatial Clustering of Applications with ... from cdn-images-1.medium.com ● density = number of points within a specified radius r (eps) ● a dbscan: The key idea is that why dbscan ? It doesn't require that you input the number. Note that, the function plot.dbscan() uses different point symbols for core points (i.e, seed points) and border points. The dbscan algorithm is based on this intuitive notion of clusters and noise. If you would like to read about other type. In dbscan, there are no centroids, and clusters are formed by linking nearby points to one another. Perform dbscan clustering from vector array or distance matrix.
Dbscan clustering is an underrated yet super useful clustering algorithm for unsupervised learning problems.
Learn how dbscan clustering works, why you should learn it, and how to implement. In this post, i will try t o explain dbscan algorithm in detail. Perform dbscan clustering from vector array or distance matrix. If p it is not a core point, assign a. The key idea is that for. It doesn't require that you input the number. The statistics and machine learning. Note that, the function plot.dbscan() uses different point symbols for core points (i.e, seed points) and border points. From dbscan import dbscan labels, core_samples_mask = dbscan(x, eps=0.3, min_samples we provide a complete example below that generates a toy data set, computes the dbscan clustering. This is the second post in a series that deals with anomaly detection, or more specifically: Firstly, we'll take a look at an example use. Finds core samples of high density and expands clusters from. The dbscan algorithm is based on this intuitive notion of clusters and noise.
The statistics and machine learning dbs. From dbscan import dbscan labels, core_samples_mask = dbscan(x, eps=0.3, min_samples we provide a complete example below that generates a toy data set, computes the dbscan clustering.







0 Komentar